

unit 25. 딕셔너리 응용하기
-
딕셔너리 조작하기
1) 딕셔너리에 키-값 쌍 추가하기
딕셔너리에 키-값 쌍을 추가하는 메서드는 2가지가 있다.
- setdefault: 키-값 쌍 추가
- update: 키의 값 수정, 키가 없으면 키-값 쌍 추가
setdefault(키)는 딕셔너리에 키-값 쌍을 추가한다. 그리고 setdefault(키, 기본값)처럼 키와 기본값을 지정하면 값에 기본값을 저장한 뒤 해당 값을 반환한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.setdefault('f', 100)
100
>>> x
{'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': None, 'f': 100}
update(키=값)은 이름 그대로 딕셔너리에서 키의 값을 수정한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.update(a=90)
>>> x
{'a': 90, 'b': 20, 'c': 30, 'd': 40}만약 딕셔너리에 키가 없으면 키-값 쌍을 추가한다.
또 update는 키-값 쌍 여러 개를 콤마로 구분해서 넣어주면 값을 한꺼번에 수정할 수 있다.
update(키=값)은 키가 문자열일 때만 사용할 수 있다.
만약 키가 숫자일 경우에는 update(딕셔너리)처럼 딕셔너리를 넣어서 값을 수정할 수 있다.
>>> y = {1: 'one', 2: 'two'}
>>> y.update({1: 'ONE', 3: 'THREE'})
>>> y
{1: 'ONE', 2: 'two', 3: 'THREE'}
다른 방법으로는 리스트와 튜플을 이용하는 방법이 있다.
update(리스트), update(튜플)은 리스트와 튜플로 값을 수정한다.
>>> y.update([[2, 'TWO'], [4, 'FOUR']])
>>> y
{1: 'ONE', 2: 'TWO', 3: 'THREE', 4: 'FOUR'}리스트는 [[키1, 값1], [키2, 값2]] 형식으로 키와 값을 리스트로 만들고 이 리스트를 다시 리스트 안에 넣어서 키-값 쌍을 나열해준다.(튜플도 같은 형식)
※ 참고 : setdefault는 키-값 쌍 추가만 할 수 있고, 이미 들어있는 키의 값은 수정할 수 없다. 하지만 update는 키-값 쌍 추가와 값 수정이 모두 가능하다.
2) 딕셔너리에 키-값 쌍 삭제하기
pop(키)는 딕셔너리에서 특정 키-값 쌍을 삭제한 뒤 삭제한 값을 반환한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.pop('a')
10
>>> x
{'b': 20, 'c': 30, 'd': 40}이때, pop(키, 기본값)처럼 기본값을 지정하면 딕셔너리에 키가 있을 때는 해당 키-값 쌍을 삭제한 뒤 삭제한 값을 반환하지만 키가 없을 때는 기본값만 반환한다.
또한 pop 대신 del로 특정 키-값 쌍을 삭제할 수도 있다. 이때는 [ ]에 키를 지정하여 del을 사용한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> del x['a']
>>> x
{'b': 20, 'c': 30, 'd': 40}
popitem()은 딕셔너리에서 임의의 키-값 쌍을 삭제한 뒤 삭제한 키-값 쌍을 튜플로 반환한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.popitem()
('d', 40)
>>> x
{'a': 10, 'b': 20, 'c': 30}clear()는 딕셔너리의 모든 키-값 쌍을 삭제한다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.clear()
>>> x
{}
3) 딕셔너리에서 키-값 쌍을 가져오기
get(키)는 딕셔너리에서 특정 키의 값을 가져온다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.get('a')
10
get(키, 기본값)처럼 기본값을 지정하면 딕셔너리에 키가 있을 때는 해당 키의 값을 반환하지만 키가 없을 때는 기본값을 반환한다.
딕셔너리는 키와 값을 다 가져오는 다양한 메서드를 제공한다.
- items: 키-값 쌍을 모두 가져옴
- keys: 키를 모두 가져옴
- values: 값을 모두 가져옴
items()는 딕셔너리의 키-값 쌍을 모두 가져온다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x.items()
dict_items([('a', 10), ('b', 20), ('c', 30), ('d', 40)])keys()는 키를 모두 가져온다.
>>> x.keys()
dict_keys(['a', 'b', 'c', 'd'])
values()는 값을 모두 가져온다.
>>> x.values()
dict_values([10, 20, 30, 40])
4) 리스트와 튜플로 딕셔너리 만들기
dict.fromkeys(키리스트)는 키 리스트로 딕셔너리를 생성하며 값은 모두 None으로 저장한다.
dict.fromkeys(키리스트, 값)처럼 키 리스트와 값을 지정하면 해당 값이 키의 값으로 저장된다.
>>> keys = ['a', 'b', 'c', 'd']
>>> y = dict.fromkeys(keys, 100)
>>> y
{'a': 100, 'b': 100, 'c': 100, 'd': 100}먼저 keys = ['a', 'b', 'c', 'd']처럼 키가 들어있는 리스트를 준비한다(튜플도 됌). 그리고 dict.fromkeys에 키가 들어있는 리스트를 넣으면 딕셔너리가 생성된다.
-
반복문으로 딕셔너리의 키-값 쌍을 모두 출력하기
items()를 통해 딕셔너리의 키-값 쌍을 모두 출력할 수 있다.
for in 뒤에 딕셔너리를 지정하고 items를 사용한다.
for 키, 값 in 딕셔너리.items():
반복할 코드다음은 for로 리스트 a의 모든 키와 값을 출력하는 코드이다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> for key, value in x.items():
... print(key, value)
...
a 10
b 20
c 30
d 40for key, value in x.items():는 딕셔너리 x에서 키-값 쌍을 꺼내서 키는 key에 값은 value에 저장하고, 꺼낼 때마다 코드를 반복한다.
* 딕셔너리의 키만 출력하기
for 반복문에서 keys를 사용하면 키만 가져올 수 있다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> for key in x.keys():
... print(key, end=' ')
...
a b c d
* 딕셔너리의 값만 출력하기
for 반복문에서 values를 사용하면 값만 가져오면서 반복할 수 있다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> for value in x.values():
... print(value, end=' ')
...
10 20 30 40
-
딕셔너리 표현식 사용하기
딕셔너리도 for 반복문과 if 조건문을 사용하여 딕셔너리를 생성할 수 있다.
- {키: 값 for 키, 값 in 딕셔너리}
- dict({키: 값 for 키, 값 in 딕셔너리})
>>> keys = ['a', 'b', 'c', 'd']
>>> x = {key: value for key, value in dict.fromkeys(keys).items()}
>>> x
{'a': None, 'b': None, 'c': None, 'd': None}딕셔너리 표현식을 사용할 때는 for in 다음에 딕셔너리를 지정하고 items를 사용한다. 그리고 키, 값을 가져온 뒤에는 키: 값 형식으로 변수나 값을 배치하여 딕셔너리를 생성하면 된다.
즉, dict.fromkeys(keys).items()로 키-값 쌍을 구한 뒤 키는 변수 key, 값은 변수 value에 꺼내고 최종적으로 key와 value를 이용하여 딕셔너리를 만든다.
물론 다음과 같이 keys로 키만 가져온 뒤 특정 값을 넣거나, values로 값을 가져온 뒤 값을 키로 사용할 수도 있다.
>>> {key: 0 for key in dict.fromkeys(['a', 'b', 'c', 'd']).keys()} # 키만 가져옴
{'a': 0, 'b': 0, 'c': 0, 'd': 0}
>>> {value: 0 for value in {'a': 10, 'b': 20, 'c': 30, 'd': 40}.values()} # 값을 키로 사용
{10: 0, 20: 0, 30: 0, 40: 0}
* 딕셔너리 표현식에서 if 문 사용하기
딕셔너리 표현식은 사실 딕셔너리에서 특정 값을 찾아서 삭제할 때 유용하다.
- {키: 값 for 키, 값 in 딕셔너리 if 조건식}
- dict({키: 값 for 키, 값 in 딕셔너리 if 조건식})
딕셔너리 표현식에서 if 조건문을 사용하여 삭제할 값을 제외하면 되기 때문이다.
>>> x = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
>>> x = {key: value for key, value in x.items() if value != 20}
>>> x
{'a': 10, 'c': 30, 'd': 40}
직접 키-값 쌍을 삭제하는 방식이 아니라 삭제할 키-값 쌍을 제외하고 남은 키-값 쌍으로 딕셔너리를 새로 만드는 것이다.
-
딕셔너리 안에서 딕셔너리 사용하기
다음과 같이 딕셔너리는 값 부분에 다시 딕셔너리가 계속 들어갈 수 있다.
- 딕셔너리 = {키1: {키A: 값A}, 키2: {키B: 값B}}
예를 들어 지구형 행성의 반지름, 질량, 공전주기를 딕셔너리로 표현해보면 다음과 같다.
terrestrial_planet = {
'Mercury': {
'mean_radius': 2439.7,
'mass': 3.3022E+23,
'orbital_period': 87.969
},
'Venus': {
'mean_radius': 6051.8,
'mass': 4.8676E+24,
'orbital_period': 224.70069,
},
'Earth': {
'mean_radius': 6371.0,
'mass': 5.97219E+24,
'orbital_period': 365.25641,
},
'Mars': {
'mean_radius': 3389.5,
'mass': 6.4185E+23,
'orbital_period': 686.9600,
}
}
print(terrestrial_planet['Venus']['mean_radius']) # 6051.8딕셔너리 terrestrial_planet에 키 'Mercury', 'Venus', 'Earth', 'Mars'가 들어있고, 이 키들은 다시 값 부분에 딕셔너리를 가지고 있다. 즉, 이를 통해 중첩 딕셔너리는 계층형 데이터를 저장할 때 유용함을 알 수 있다.
딕셔너리 안에 들어있는 딕셔너리에 접근하려면 딕셔너리 뒤에 [ ](대괄호)를 단계만큼 붙이고 키를 지정해주면 된다.
- 딕셔너리[키][키]
- 딕셔너리[키][키] = 값
-
딕셔너리의 할당과 복사
리스트와 마찬가지로 딕셔너리도 할당과 복사는 큰 차이점이 있다.
먼저 딕셔너리를 만든 뒤 다른 변수에 할당한다.
>>> x = {'a': 0, 'b': 0, 'c': 0, 'd': 0}
>>> y = xy = x와 같이 딕셔너리를 다른 변수에 할당하면 딕셔너리는 두 개가 될 것 같지만 실제로는 딕셔너리가 한 개다. x와 y를 is 연산자로 비교해보면 True가 나온다.
따라서 딕셔너리 x와 y를 완전히 두 개로 만들려면 copy 메서드로 모든 키-값 쌍을 복사해야 한다.
>>> x = {'a': 0, 'b': 0, 'c': 0, 'd': 0}
>>> y = x.copy()이제 x와 y를 is 연산자로 비교해보면 False가 나온다. 즉, 두 딕셔너리는 다른 객체이다.
* 중첩 딕셔너리의 할당과 복사 알아보기
중첩 딕셔너리를 완전히 복사하려면 다음과 같이 copy 메서드 대신 copy 모듈의 deepcopy 함수를 사용해야 한다.
>>> x = {'a': {'python': '2.7'}, 'b': {'python': '3.6'}}
>>> import copy # copy 모듈을 가져옴
>>> y = copy.deepcopy(x) # copy.deepcopy 함수를 사용하여 깊은 복사
>>> y['a']['python'] = '2.7.15'
>>> x
{'a': {'python': '2.7'}, 'b': {'python': '3.6'}}
>>> y
{'a': {'python': '2.7.15'}, 'b': {'python': '3.6'}}
unit 26. 세트 사용하기
-
세트 만들기
세트(set) 자료형은 영어로 하면 집합을 뜻하며, 합집합, 교집합, 차집합 등의 연산이 가능하다.
세트는 { }(중괄호) 안에 값을 저장하며 각 값은 ,(콤마)로 구분해준다.
- 세트 = {값1, 값2, 값3}
다음은 과일이 들어있는 세트를 나타낸 것이다.
>>> fruits = {'strawberry', 'grape', 'orange', 'pineapple', 'cherry'}
>>> fruits
{'pineapple', 'orange', 'grape', 'strawberry', 'cherry'}세트는 요소의 순서가 정해져 있지 않다(unordered). 따라서 세트를 출력해보면 매번 요소의 순서가 다르게 나온다.
또한, 세트에 들어가는 요소는 중복될 수 없으며, 특히 세트는 리스트, 튜플, 딕셔너리와는 달리 [ ](대괄호)로 특정 요소만 출력할 수는 없다.
* 세트에 특정 값이 있는지 확인하기
그래서 세트에 특정 값이 있는지 확인하려면 in 연산자를 사용하면 된다.
>>> fruits = {'strawberry', 'grape', 'orange', 'pineapple', 'cherry'}
>>> 'orange' in fruits
True
>>> 'peach' in fruits
False반대로 in 앞에 not을 붙이면 특정 값이 없는지 확인한다.
* set를 사용하여 세트 만들기
- set(반복가능한객체)
set에는 반복 가능한 객체(iterable)를 넣는다.
set('apple')과 같이 영문 문자열을 세트로 만들면 'apple'에서 유일한 문자인 'a', 'p', 'l', 'e'만 세트로 만들어진다. (즉, 중복된 문자는 포함되지 않음)
>>> a = set('apple') # 유일한 문자만 세트로 만듦
>>> a
{'e', 'l', 'a', 'p'}그리고 set(range(5))와 같이 숫자를 만들어내는 range를 사용하면 0부터 4까지 숫자를 가진 세트를 만들 수 있다.
빈 세트는 c = set()과 같이 set에 아무것도 지정하지 않으면 된다.
>>> c = set()
>>> c
set()※주의 : 단, 세트가 { }를 사용한다고 해서 c = {}와 같이 만들면 빈 딕셔너리가 만들어지므로 주의해야 한다. 만약 세트인지 딕셔너리인지 알고 싶을 땐 type을 사용하면 자료형의 종류를 알 수 있다.
-
집합 연산 사용하기
1) 집합 연산과 메서드
이제 세트에서 집합 연산과 이에 대응하는 메서드를 사용해보겠다.
| 연산자는 합집합(union)을 구하며 OR 연산자 |를 사용한다. 그리고 set.union 메서드와 동작이 같다.
- 세트1 | 세트2
- set.union(세트1, 세트2)
>>> a = {1, 2, 3, 4}
>>> b = {3, 4, 5, 6}
>>> a | b
{1, 2, 3, 4, 5, 6}
>>> set.union(a, b)
{1, 2, 3, 4, 5, 6}다음은 세트 {1, 2, 3, 4}와 {3, 4, 5, 6}을 모두 포함하므로 {1, 2, 3, 4, 5, 6}이 나온다.
& 연산자는 교집합(intersection)을 구하며 AND 연산자 &를 사용한다. set.intersection 메서드와 동작이 같다.
- 세트1 & 세트2
- set.intersection(세트1, 세트2)
>>> a & b
{3, 4}
>>> set.intersection(a, b)
{3, 4}다음은 세트 {1, 2, 3, 4}와 {3, 4, 5, 6} 중에서 겹치는 부분을 구하므로 {3, 4}가 나온다.
- 연산자는 차집합(difference)을 구하며 뺄셈 연산자 -를 사용한다. set.difference 메서드와 동작이 같다.
- 세트1 - 세트2
- set.difference(세트1, 세트2)
>>> a - b
{1, 2}
>>> set.difference(a, b)
{1, 2}다음은 {1, 2, 3, 4}에서 {3, 4, 5, 6}과 겹치는 3과 4를 뺐으므로 {1, 2}가 나온다.
^ 연산자는 대칭차집합(symmetric difference)을 구하며 XOR 연산자 ^를 사용합니다. set.symmetric_difference 메서드와 동작이 같다.
- 세트1 ^ 세트2
- set.symmetric_difference(세트1, 세트2)
>>> a ^ b
{1, 2, 5, 6}
>>> set.symmetric_difference(a, b)
{1, 2, 5, 6}XOR은 서로 다르면 참이다. 따라서 집합에서는 두 집합 중 겹치지 않는 요소만 포함한다. 다음은 세트 {1, 2, 3, 4}와 {3, 4, 5, 6} 중에서 같은 값 3과 4를 제외한 다른 모든 요소를 구하므로 {1, 2, 5, 6}이 나온다.
2) 집합 연산 후 할당 연산자 사용하기
세트 자료형에 |, &, -, ^ 연산자와 할당 연산자 =을 함께 사용하면 집합 연산의 결과를 변수에 다시 저장(할당)한다.
|=은 현재 세트에 다른 세트를 더하며 update 메서드와 같다.
- 세트1 |= 세트2
- 세트1.update(세트2)
&=은 현재 세트와 다른 세트 중에서 겹치는 요소만 현재 세트에 저장하며 intersection_update 메서드와 같다.
- 세트1 &= 세트2
- 세트1.intersection_update(세트2)
-=은 현재 세트에서 다른 세트를 빼며 difference_update 메서드와 같다.
- 세트1 -= 세트2
- 세트1.difference_update(세트2)
^=은 현재 세트와 다른 세트 중에서 겹치지 않는 요소만 현재 세트에 저장하며 symmetric_difference_update 메서드와 같다.
- 세트1 ^= 세트2
- 세트1.symmetric_difference_update(세트2)
3) 부분집합과 상위집합 확인하기
세트는 부분집합, 진부분집합, 상위집합, 진상위집합과 같이 속하는 관계를 표현할 수 있다.
<=은 현재 세트가 다른 세트의 부분집합(subset)인지 확인하며 issubset 메서드와 같다.
- 현재세트 <= 다른세트
- 현재세트.issubset(다른세트)
>>> a = {1, 2, 3, 4}
>>> a <= {1, 2, 3, 4}
True
>>> a.issubset({1, 2, 3, 4, 5})
True다음은 세트 {1, 2, 3, 4}가 {1, 2, 3, 4}의 부분집합이므로 참이다(등호가 있으므로 두 세트가 같을 때도 참임)
<은 현재 세트가 다른 세트의 진부분집합(proper subset)인지 확인하며 메서드는 없다.
>=은 현재 세트가 다른 세트의 상위집합(superset)인지 확인하며 issuperset 메서드와 같다.
>은 현재 세트가 다른 세트의 진상위집합(proper superset)인지 확인하며 메서드는 없다.
* 세트가 같은지 혹은 겹치지 않는지 확인하기
세트는 == 연산자를 사용하여 서로 같은지 확인할 수 있다.
disjoint는 현재 세트가 다른 세트와 겹치지 않는지 확인한다. 겹치는 요소가 없으면 True, 있으면 False이다.
- 현재세트.isdisjoint(다른세트)
>>> a = {1, 2, 3, 4}
>>> a.isdisjoint({5, 6, 7, 8}) # 겹치는 요소가 없음
True
>>> a.isdisjoint({3, 4, 5, 6}) # a와 3, 4가 겹침
False
-
세트 조작하기
* 세트에 요소 추가하기
add(요소)는 세트에 요소를 추가한다.
>>> a = {1, 2, 3, 4}
>>> a.add(5)
>>> a
{1, 2, 3, 4, 5}
* 세트에서 특정 요소를 삭제하기
remove(요소)는 세트에서 특정 요소를 삭제하고 요소가 없으면 에러를 발생시킨다.
>>> a.remove(3)
>>> a
{1, 2, 4, 5}discard(요소)는 세트에서 특정 요소를 삭제하고 요소가 없으면 그냥 넘어간다.
* 세트에서 임의의 요소 삭제하기
pop()은 세트에서 임의의 요소를 삭제하고 해당 요소를 반환한다. 만약 요소가 없으면 에러를 발생시킨다.
>>> a = {1, 2, 3, 4}
>>> a.pop()
1
>>> a
{2, 3, 4}
* 세트의 모든 요소를 삭제하기
clear()는 세트에서 모든 요소를 삭제한다.
>>> a.clear()
>>> a
set()
* 세트의 요소 개수 구하기
len(세트)는 세트의 요소 개수(길이)를 구한다.
>>> a = {1, 2, 3, 4}
>>> len(a)
4
-
세트의 할당과 복사
세트도 리스트, 딕셔너리처럼 할당과 복사의 차이점이 있다.
먼저 세트를 만든 뒤 다른 변수에 할당한다.
>>> a = {1, 2, 3, 4}
>>> b = ab = a와 같이 세트를 다른 변수에 할당하면 세트는 두 개가 될 것 같지만 실제로는 세트가 한 개다. a와 b를 is 연산자로 비교해보면 True가 나온다.
세트 a와 b를 완전히 두 개로 만들려면 copy 메서드로 모든 요소를 복사해야 한다.
>>> a = {1, 2, 3, 4}
>>> b = a.copy()이제 a와 b를 is 연산자로 비교해보면 False가 나온다. 즉, 두 세트는 다른 객체이다.
-
반복문으로 세트의 요소를 모두 출력하기
이번에는 세트와 for 반복문을 사용하여 요소를 출력해보겠다.
간단하게 for in 뒤에 세트만 지정하면 된다.
for 변수 in 세트:
반복할 코드다음은 for로 세트 a의 요소를 출력한다.
>>> a = {1, 2, 3, 4}
>>> for i in a:
... print(i)
...
1
2
3
4for i in a:는 세트 a에서 요소를 꺼내서 i에 저장하고, 꺼낼 때마다 코드를 반복한다. 따라서 print로 i를 출력하면 요소를 모두 출력할 수 있다.
단, 세트의 요소는 순서가 없으므로 출력할 때마다 순서가 달라진다(숫자로만 이루어진 세트는 순서대로 출력됨).
-
세트 표현식 사용하기
세트는 for 반복문과 if 조건문을 사용하여 세트를 생성할 수 있다.
다음과 같이 세트 안에 식과 for 반복문을 지정하면 된다.
- {식 for 변수 in 반복가능한객체}
- set(식 for 변수 in 반복가능한객체)
>>> a = {i for i in 'apple'}
>>> a
{'l', 'p', 'e', 'a'}
단, 중복된 문자는 세트에 포함되지 않는다.
* 세트 표현식에 if 조건문 사용하기
다음과 같이 if 조건문은 for 반복문 뒤에 지정한다.
- {식 for 변수 in 세트 if 조건식}
- set(식 for 변수 in 세트 if 조건식)
>>> a = {i for i in 'pineapple' if i not in 'apl'}
>>> a
{'e', 'i', 'n'}문자열 'pineapple'에서 'a', 'p', 'l'을 제외한 문자들로 세트를 생성한다.
즉, 다음과 같이 for 반복문 뒤에 if 조건문을 지정하면 if 조건문에서 특정 요소를 제외한 뒤 세트를 생성한다.
unit 27. 파일 사용하기
-
파일에 문자열 쓰기, 읽기
1) 파일에 문자열 쓰기
파일에 문자열을 쓸 때는 open 함수로 파일을 열어서 파일 객체(file object)를 얻은 뒤에 write 메서드를 사용한다.
- 파일객체 = open(파일이름, 파일모드)
- 파일객체.write('문자열')
- 파일객체.close()
file = open('hello.txt', 'w') # hello.txt 파일을 쓰기 모드(w)로 열기. 파일 객체 반환
file.write('Hello, world!') # 파일에 문자열 저장
file.close() # 파일 객체 닫기hello.txt 파일을 열어보면 'Hello, world!' 문자열이 저장된 것을 볼 수 있다.
파일에 문자열을 쓰는 과정은 다음과 같다.

2) 파일에서 문자열 읽기
이번에는 앞에서 만든 hello.txt 파일의 문자열을 읽어보겠다.
파일을 읽을 때도 open 함수로 파일을 열어서 파일 객체를 얻은 뒤 read 메서드로 파일의 내용을 읽는다. 단, 이때는 파일 모드를 읽기 모드 'r'로 지정해야 한다.
- 변수 = 파일객체.read()
file = open('hello.txt', 'r') # hello.txt 파일을 읽기 모드(r)로 열기. 파일 객체 반환
s = file.read() # 파일에서 문자열 읽기
print(s) # Hello, world!
file.close() # 파일 객체 닫기파일에서 문자열을 읽는 과정은 다음과 같다.

3) 자동으로 파일 객체 닫기
파이썬에서는 with as를 사용하면 파일을 사용한 뒤 자동으로 파일 객체를 닫아준다.
다음과 같이 with 다음에 open으로 파일을 열고 as 뒤에 파일 객체를 지정하면 된다.
with open(파일이름, 파일모드) as 파일객체:
코드
앞에서 만든 hello.txt 파일을 읽어보겠다.
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
s = file.read() # 파일에서 문자열 읽기
print(s) # Hello, world!파일을 읽고나서 close를 사용하지 않았지만 자동으로 닫힌 것을 알 수 있다.
-
문자열 여러줄을 파일에 쓰기, 읽기
* 반복문으로 문자열 여러 줄을 파일에 쓰기
with open('hello.txt', 'w') as file: # hello.txt 파일을 쓰기 모드(w)로 열기
for i in range(3):
file.write('Hello, world! {0}\n'.format(i))파일에 문자열 여러 줄을 저장할 때 주의할 부분은 개행 문자 부분이다. 'Hello, world! {0}\n'와 같이 문자열 끝에 개행 문자 \n를 지정해주어야 줄바꿈이 된다.
* 리스트에 들어있는 문자열을 파일에 쓰기
- 파일객체.writelines(문자열리스트)
lines = ['안녕하세요.\n', '파이썬\n', '코딩 도장입니다.\n']
with open('hello.txt', 'w') as file: # hello.txt 파일을 쓰기 모드(w)로 열기
file.writelines(lines)writelines는 리스트에 들어있는 문자열을 파일에 쓴다. 그리고 writelines를 사용할 때는 반드시 리스트의 각 문자열 끝에 개행 문자 \n을 붙여주어야 한다.
* 파일의 내용을 한 줄씩 리스트로 가져오기
파일의 내용을 한 줄씩 순차적으로 읽으려면 readlines을 사용한다.
- 변수 = 파일객체.readlines()
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
lines = file.readlines()
print(lines)readline은 파일의 내용을 한 줄씩 리스트 형태로 가져온다.
['안녕하세요.\n', '파이썬\n', '코딩 도장입니다.\n']
* 파일의 내용을 한 줄씩 읽기
파일의 내용을 한 줄씩 순차적으로 읽으려면 readline을 사용한다.
- 변수 = 파일객체.readline()
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
line = None # 변수 line을 None으로 초기화
while line != '':
line = file.readline()
print(line.strip('\n')) # 파일에서 읽어온 문자열에서 \n 삭제하여 출력readline으로 파일을 읽을 때는 while 반복문을 활용해야 한다. 왜냐하면 파일에 문자열이 몇 줄이나 있는지 모르기 때문이다. 그래서 line != ''와 같이 빈 문자열이 아닐 때 계속 반복하도록 만든다.
그리고 특히 변수 line은 while로 반복하기 전에 None으로 초기화준다. 만약 변수 line을 만들지 않고 while을 실행하면 없는 변수와 빈 문자열 ''을 비교하게 되므로 에러가 발생한다.
또한, line을 None이 아닌 ''로 초기화하면 처음부터 line != ''는 거짓이 되므로 반복을 하지 않고 코드가 그냥 끝나버린다. while을 사용할 때는 이 부분을 주의해야한다.
* for 반복문으로 파일의 내용을 줄 단위로 읽기
다음은 for 반복문에 파일 객체를 지정하여 줄 단위로 파일의 내용을 읽는다.
with open('hello.txt', 'r') as file: # hello.txt 파일을 읽기 모드(r)로 열기
for line in file: # for에 파일 객체를 지정하면 파일의 내용을 한 줄씩 읽어서 변수에 저장함
print(line.strip('\n')) # 파일에서 읽어온 문자열에서 \n 삭제하여 출력이렇게 for 반복문에 파일 객체를 지정하면 반복을 할 때마다 파일의 내용을 한 줄씩 읽어서 변수에 저장해준다.
-
파이썬 객체를 파일에 저장하기, 가져오기
파이썬 객체를 파일에 저장할 땐 pickle 모듈을 사용한다.
다음과 같이 파이썬 객체를 파일에 저장하는 과정을 피클링(pickling)이라고 하고, 파일에서 객체를 읽어오는 과정을 언피클링(unpickling)이라고 한다.
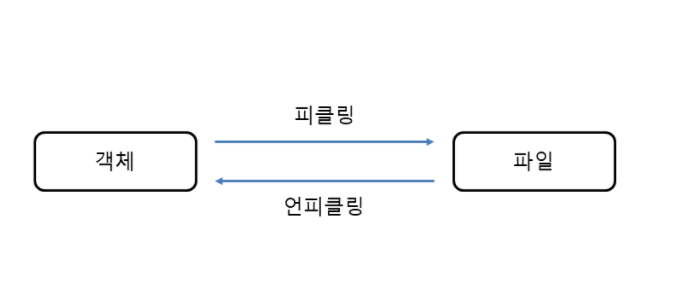
* 파이썬 객체를 파일에 저장하기
다음은 파이썬 객체를 파일에 저장하는 피클링을 하는 코드이다.
피클링은 pickle 모듈의 dump 메서드를 사용한다.
import pickle
name = 'james'
age = 17
address = '서울시 서초구 반포동'
scores = {'korean': 90, 'english': 95, 'mathematics': 85, 'science': 82}
with open('james.p', 'wb') as file: # james.p 파일을 바이너리 쓰기 모드(wb)로 열기
pickle.dump(name, file)
pickle.dump(age, file)
pickle.dump(address, file)
pickle.dump(scores, file)
pickle.dump로 객체(값)를 저장할 때는 open('james.p', 'wb')와 같이 파일 모드를 'wb'로 지정해야 한다. b는 바이너리(binary)를 뜻하는데, 바이너리 파일은 컴퓨터가 처리하는 파일 형식이다.
따라서 메모장 같은 텍스트 편집기로 열어도 사람이 알아보기 어렵다.
* 파일에서 파이썬 객체 읽기
파일에서 파이썬 객체를 읽어오는 언피클링은 pickle 모듈의 load를 사용한다.
그리고 언피클링을 할 때는 반드시 파일 모드를 바이너리 읽기 모드 'rb'로 지정해야 한다.
import pickle
with open('james.p', 'rb') as file: # james.p 파일을 바이너리 읽기 모드(rb)로 열기
name = pickle.load(file)
age = pickle.load(file)
address = pickle.load(file)
scores = pickle.load(file)
print(name)
print(age)
print(address)
print(scores)실행 결과는 다음과 같다.
james
17
서울시 서초구 반포동
{'korean': 90, 'english': 95, 'mathematics': 85, 'science': 82}앞에서 james.p 파일을 저장할 때 pickle.dump를 네 번 사용했던 것과 마찬가지로 파일에서 객체(값)를 가져올 때도 pickle.load를 네 번 사용해야 한다.
그리고 name, age, address, scores 순으로 저장했으므로 가져올 때도 같은 순서로 가져오면 된다.
unit 28. 회문 판별과 N-gram 만들기
-
회문 판별하기
회문(palindrome)은 순서를 거꾸로 읽어도 제대로 읽은 것과 같은 단어와 문장을 말한다. 예를 들어 "level", "SOS", "rotator", "nurses run"과 같은 단어와 문장이 있다.
먼회문을 잘 살펴보면 첫 번째 글자와 마지막 글자가 같다. 그리고 안쪽으로 한 글자씩 좁혔을 때 글자가 서로 같으면 회문이다.
* 반복문으로 문자 검사하기
word = input('단어를 입력하세요: ')
is_palindrome = True # 회문 판별값을 저장할 변수, 초깃값은 True
for i in range(len(word) // 2): # 0부터 문자열 길이의 절반만큼 반복
if word[i] != word[-1 - i]: # 왼쪽 문자와 오른쪽 문자를 비교하여 문자가 다르면
is_palindrome = False # 회문이 아님
break
print(is_palindrome) # 회문 판별값 출력실행결과는 다음과 같다.
단어를 입력하세요: level (입력)
True
회문 판별에서 가장 중요한 부분은 문자열(단어)의 길이다. 왜냐하면 회문 판별은 문자열의 길이를 기준으로 하기 때문이다. 즉, 문자열을 절반으로 나누어서 왼쪽 문자와 오른쪽 문자가 같은지 검사해야 한다.
그리고 for 반복문의 i가 0부터 1씩 증가하므로 word[i]는 왼쪽에서 오른쪽으로 진행하고, word[-1 - i]는 오른쪽에서 -1씩 왼쪽으로 진행해 비교한다.
* 시퀀스 뒤집기로 문자 검사하기
회문은 시퀀스 객체의 슬라이스를 활용하면 간단하게 판별할 수 있다.
word = input('단어를 입력하세요: ')
print(word == word[::-1]) # 원래 문자열과 반대로 뒤집은 문자열을 비교실행 결과는 위와 동일하다.
word[::-1]은 문자열 전체에서 인덱스를 1씩 감소시키면서 요소를 가져오므로 문자열을 반대로 뒤집는다.
그래서 원래 문자열 word와 뒤집은 문자열 word[::-1]을 비교해 같으면 회문이다.
* 리스트와 reversed 사용하기
다음과 같이 반복 가능한 객체의 요소 순서를 반대로 뒤집는 reversed를 사용해도 된다.
>>> word = 'level'
>>> list(word) == list(reversed(word))
Truereversed로 문자열을 반대로 뒤집어서 list에 넣으면 문자 순서가 반대로 된 리스트를 구할 수 있다.
+ list에 문자열을 넣으면 문자 하나 하나가 리스트의 요소로 들어간다.
* 문자열의 join 메서드와 reversed 사용하기
문자열의 join 메서드를 사용해서 회문을 판별할 수도 있다.
>>> word = 'level'
>>> word == ''.join(reversed(word))
True>>> word
'level'
>>> ''.join(reversed(word))
'level'join이 빈 문자열 ''에 reversed(word)의 요소를 연결하므로써 문자 순서가 반대로 된 문자열을 얻을 수 있다.
즉, join은 요소 사이에 구분자를 넣지만 빈 문자열 ''을 활용하여 각 문자를 그대로 연결하는 방식이다.
-
N-gram 만들기
N-gram은 문자열에서 N개의 연속된 요소를 추출하는 방법이다.
만약 'Hello'라는 문자열을 문자(글자) 단위 2-gram으로 추출하면 다음과 같다.
He
el
ll
lo즉, 문자열의 처음부터 문자열 끝까지 한 글자씩 이동하면서 2글자를 추출하는 것이다.
* 반복문으로 N-gram 출력하기
반복문으로 문자 단위 2-gram을 출력해보겠다.
text = 'Hello'
for i in range(len(text) - 1): # 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복함
print(text[i], text[i + 1], sep='') # 현재 문자와 그다음 문자 출력실행 결과는 위와 동일하다. 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복하면서 현재 문자와 그다음 문자 두 글자씩 출력하면 된다.
다음은 문자열을 공백으로 구분하여 단어 단위 2-gram을 출력한다.
text = 'this is python script'
words = text.split() # 공백을 기준으로 문자열을 분리하여 리스트로 만듦
for i in range(len(words) - 1): # 2-gram이므로 리스트의 마지막에서 요소 한 개 앞까지만 반복함
print(words[i], words[i + 1]) # 현재 문자열과 그다음 문자열 출력실행 결과는 다음과 같다.
this is
is python
python scriptsplit을 사용하여 공백을 기준으로 문자열을 분리하여 리스트로 만드는 것외에 글자 단위 2-gram과 동일하다.
* zip으로 2-gram 만들기
zip 함수로 2-gram을 만드는 방법은 다음과 같다.
text = 'hello'
two_gram = zip(text, text[1:])
for i in two_gram:
print(i[0], i[1], sep='')실행 결과는 위와 동일하다.
zip 함수는 반복 가능한 객체의 각 요소를 튜플로 묶어준다.
zip(text, text[1:])은 문자열 text와 text[1:]의 각 요소를 묶어서 튜플로 만든다. 즉, 문자 하나가 밀린 상태로 각 문자를 묶는 것이다.
* zip과 리스트 표현식으로 N-gram 만들기
N-gram을 만들 때 zip에 일일이 [1:], [2:]같은 슬라이스를 넣자니 상당히 번거롭다.
그래서 이 과정을 코드로 만들 필요가 있는데, 다음과 같이 리스트 표현식을 사용하면 된다.
>>> text = 'hello'
>>> [text[i:] for i in range(3)]
['hello', 'ello', 'llo'][text[i:] for i in range(3)]처럼 for로 3번 반복하면서 text[i:]로 리스트를 생성한다.
여기서 for i in range(3)는 0, 1, 2까지 반복하므로 text[i:]는 text[0:], text[1:], text[2:]가 되고 이는 3-gram에 필요한 슬라이스이다.
그리고 만들어진 리스트 ['hello', 'ello', 'llo']를 zip에 넣어을 때 주의할 것이다.
zip은 반복 가능한 객체 여러 개를 콤마로 구분해서 넣어줘야 한다.
하지만 ['hello', 'ello', 'llo']은 요소가 3개 들어있는 리스트 1개이다.
따라서 zip에 리스트의 각 요소를 콤마로 구분해서 넣어주기 위해 리스트 앞에 *를 붙여야 한다.
>>> list(zip(*['hello', 'ello', 'llo']))
[('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]*을 붙여서 넣어주면 3-gram 리스트가 만들어진다.
'Programming Languages > Python' 카테고리의 다른 글
| [P4C] 파이썬 코딩 도장 : UNIT 29 ~ UNIT 31 (0) | 2021.01.28 |
|---|---|
| [P4C] 파이썬 코딩 도장 : 문제 풀이3 (0) | 2021.01.28 |
| [P4C] 파이썬 코딩 도장 : 문제 풀이2 (0) | 2021.01.27 |
| [P4C] 파이썬 코딩 도장 : UNIT 22 ~ UNIT 24 (0) | 2021.01.26 |
| [P4C] 파이썬 코딩 도장 : UNIT 19 ~ UNIT 21 (0) | 2021.01.25 |